

Executive Summary
This webinar covers key principles, applications, and governance of data modelling and management. Howard Diesel discusses data stewardship, database systems, open data search strategies, Power BI, Enterprise Data Models, implementation styles, data integration, quality, governance, architecture, and security. Additionally, he discusses centralised hubs, data-sharing architecture, Master Data systems, the analytical vs. operational data life cycle, business process optimisation, and agile Data Management approaches. The webinar explores the importance of strategic Data Management, key roles, and challenges in implementing effective Data Management systems.
Webinar Details
Title: Reference & Master Data Management for Data Professionals
Date: 26 September 2024
Presenter: Howard Diesel
Meetup Group: Data Professionals
Write-up Author: Howard Diesel
Contents
- Data Modelling and Management: Principles, Applications, and Governance
- Data Management and Stewardship
- Data Models and Management Strategies in Database Systems
- Data Modelling and Open Data Search Strategies
- Code Tables in Data Management and Power BI
- Enterprise Data Model and Master Data Implementation
- Understanding Data Modelling: Identifiers and Field Types
- Data Modelling and Implementation Styles
- Data Integration, Quality, and Hierarchy in Knowledge Areas
- Data Governance and Knowledge Areas
- Data Architecture and Quality Management
- Capabilities and Operations of Modern Data Management Systems
- Features and Benefits of Informatica’s Data Integration and Management System
- Role and Implementation of Centralised Hubs in Data Management
- Data Integration and Management Strategies
- Data Sharing Architecture and Storage Solutions
- Data Management and Security in Data Warehouse
- Challenges and Strategies in Implementing Master Data Systems
- The Debate of Analytical vs Operational: A Discussion on Data Life Cycle
- Strategic Data Management and Business Process Optimisation
- The Importance of Agile Data Management and Product Management Approach
- Key Roles and Management in Data Management
- Data Architecture and Dependency Management
- Use of Master Data as Dimension Tables in Customer Analysis
- The Importance of Business Process over Domain in Data Architecture
- Challenges and Strategies in Data Management
Data Modelling and Management: Principles, Applications, and Governance
Howard Diesel opens and shares the plan for the webinar. ‘Reference and Master Data Management for Data Professionals’ will cover data modelling principles, relationships with other knowledge areas, incremental plans for success in reference and Master Data, and the difference between operational and analytical Master Data Management. Additionally, Howard mentions that next week’s discussion would revolve around using data-driven executives, focusing on the business case and ROI.

Figure 1 Master & Reference Data Management Series: Data Professional
Data Management and Stewardship
In the past two weeks, this webinar series has covered various aspects of Data Management, including the key points from a data manager’s perspective, readiness assessment, decision mandates, and data stewardship. Data stewardship can be challenging initially as it involves shifting responsibilities to business personnel and addressing issues like data cleaning and matching. Without proper support and involvement, managing multiple data rows for the same customer can become complex. Next week, ‘Reference & Master Data Management’ will discuss the roles of data executives.
Data Models and Management Strategies in Database Systems
Data models and other knowledge areas are explored as Howard distinguishes between analytical and operational versus analytical Master Data Management (MDM) in the incremental rollout. Delving into data models, reference and Master Data, Howard emphasises the need for clear principles in data modelling to distinguish between Reference Data code tables, Master Data, and transaction tables. Utilising schemas in databases to organise Reference Data, Master Data, and transaction tables will help to make clear distinctions. Howard touches upon the debate around consolidating code tables into a single table and suggests unique IDs for every code in the system. Additionally, he notes the need for a Reference Data product registry to manage metadata.

Figure 2 Master & Reference Data Architect and Modeller

Figure 3 Reference Data Modelling Principles
Data Modelling and Open Data Search Strategies
When dealing with different sources for data modelling, it’s important to consider the layout and structure specific to each source, such as ISO or external providers. Maintaining the original layout from external sources is crucial, while modelling by type is preferred internally. Creating separate tables for code decode type, taxonomies, and ontologies helps to organise the data effectively. Additionally, it’s essential to recognise that data from external sources becomes Reference Data within the organisation and utilise tools like Google Data Set Search and Data Hub to find open data sets, including those from sources like Kaggle, data.gov, and the UCI machine learning repository.

Figure 4 Dataset Search for Open Free Data
Code Tables in Data Management and Power BI
Howard shares on a set of code tables released by Malcolm Chisholm to connect Power BI that he has made use of. This set includes 42 health-related tables, 37 economy-related tables, units of measure tables, language tables, and environment tables, totalling around 240. The goal was to ensure each code table has a URL for easy access. Establishing a strong set of Reference Data tables is crucial for organisations when setting up Master Data models, allowing for efficient use of Reference Data whenever needed, thus eliminating the need for special requests and saving time.

Figure 5 Free Dataset Search

Figure 6 Proportion of Available Code Tables by Concept

Figure 7 Proportion of Available Code Tables by Concept Continued
Enterprise Data Model and Master Data Implementation
In the context of Master Data, starting with the Enterprise Data Model is suggested. It provides standardised layouts for the entire organisation. The data architect’s work on the Enterprise Data Model is essential, and subsequent Master Data domains should stem from it. While the absence of an Enterprise Data Model is common, establishing one is highly recommended. When different subject areas are involved, using abstraction is key to avoid overlapping business concepts and disagreements over responsibilities. Additionally, Master Data for data privacy encompasses various entities, such as employees, vendors, customers, and contacts, and it’s important to consider these aspects for data privacy compliance.

Figure 8 Master Data Modelling Principles
Understanding Data Modelling: Identifiers and Field Types
Identifying the entity’s natural or business key in data modelling is crucial for entity resolution. This key acts as the candidate key/alternate key, ensuring a single match. However, in cases of Master Data, additional attributes such as addresses, or gender may be necessary to distinguish differences and create a comprehensive golden record and profile for the entity. This includes identifiers, records, and profiles, encompassing all mastered data for the entity, which is especially useful in data vault scenarios.
Data Modelling and Implementation Styles
In making important decisions about implementation, it’s crucial to consider the implementation style that will be used. Different factors must be considered depending on the chosen style (e.g., registry, central, virtual, hybrid, hub, or repository). For instance, with a registry implementation, the focus is primarily on the identifier and the pointer to the source system, as the data remains in the source systems. On the other hand, in a central or virtual implementation, emphasis should be placed on the Enterprise Data Model. A diagram emphasised that all Master Data are critical, with identifiers being the highest priority, followed by the core and all other data elements.

Figure 9 MDM Implementation Style
Data Integration, Quality, and Hierarchy in Knowledge Areas
Howard focuses on mapping dependencies to knowledge areas, particularly in relation to Master Data, Reference Data, data integration, and data sharing. He emphasises the importance of data quality and architecture, delving into the role of governance, stewards, principles, and policies. Additionally, the benefits of data warehousing, especially regarding hierarchy definition and using Master Data environments will simplify hierarchy building. Howard mentions the challenges of coding for hierarchies across different areas and adds the importance of security and privacy.
Data Governance and Knowledge Areas
The Data Governance plan is divided into different knowledge areas based on the life cycle stages, including planning, design, creation, storage, use, enhancement, and disposal. It is crucial to integrate Master Data and Reference Data with Data Governance, aligning it with the business case and data strategy. Implementing a small data strategy with a set of use cases can be completed within approximately 90 days, focusing on a portfolio of 100-120 use cases to determine commercial feasibility and value delivery. The Data Governance process involves defining Principles, Policies, Procedures and Technology (P3T), implementation framework, and reference architecture, all of which are coordinated with the data architect’s input based on business requirements and technology needs. Additionally, establishing an operating model, ownership, stewardship, and decision-making mandates is essential, especially for Master Data. Furthermore, creating a business glossary with clear definitions of core business concepts and their relationships is crucial for standardisation and avoiding debates during the Enterprise Data Model implementation.

Figure 10 Reference and Master Data and other Knowledge Areas

Figure 11 Knowledge Areas in the Plan phase of the Lifecycle
Data Architecture and Quality Management
The data architect plays a crucial role in developing subject area models and the Enterprise Data Model (EDM). They focus on identifying domains and required capabilities within the organisation and managing Reference Data and Master Data components. The architect also considers data distribution, harmonisation, quality expectations, and source trust. This includes defining rules for data trust levels and establishing a system of record for specific data sources. Additionally, the architect is involved in ensuring data quality through processes such as data matching, entity resolution, survivorship, and creating golden records and profiles.
Capabilities and Operations of Modern Data Management Systems
The typical capabilities of Master Data Management (MDM) involve operational management, data integration and acquisition, data consolidation, data quality checks, and storage and operations. The MDM architecture includes elements such as data model, Reference Data, Metadata Management, business rules, hierarchy, and repository. Additionally, MDM services encompass versioning, slowly changing dimensions, access control, data delivery, and data synchronisation. MDM supports operational and analytical aspects, harmonising and standardising applications, and integrating with data warehouse and business intelligence for hierarchical Data Management.

Figure 12 Typical Master Data Management Capabilities
Features and Benefits of Informatica’s Data Integration and Management System
Informatica’s strong performance in Data Management is emphasised. It supports various data sources, including unstructured data, Reference and Master Data, and external data. Integrating with Master Data systems can ensure data accuracy and relevance. The concept of “360” is suggested as the process of gathering all the information about a customer, a product, a contract or finances for comprehensive coverage. Informatica’s approach to data integration, tokenisation, and the development of a complete view of customer behaviour through applications such as Customer Data Platforms (CDP) is discussed. Additionally, it’s imperative to be aware of the challenges associated with managing data across different applications and data privacy concerns. Howard suggests Informatica, as its comprehensive approach aims to streamline data consolidation and provide insights while addressing data privacy and security concerns.

Figure 13 Informatica Master Data Management

Figure 14 Informatica Master Data Management highlighting Data Quality

Figure 15 Informatica Master Data Management highlighting 360 SaaS

Figure 16 Informatica Master Data Management Integration with applications
Role and Implementation of Centralised Hubs in Data Management
Howard provides an overview of different approaches to Master Data Management (MDM). He highlights the challenges of relying solely on a centralised hub and suggests alternative methods, such as synchronised masters for specific applications and industry-specific standards like ISO 25,500. He emphasises the importance of real-time data movement using an ESB, data virtualisation, and local hubs to support regional data warehouses. Howard also stresses the distinction between getting a prototype up and running and the implementation process, emphasising the need to understand how data sharing will occur.

Figure 17 Synchronised Master and Application Specific Master

Figure 18 Hub-Based Master and Master Overlay

Figure 19 Real-Time Data Movement and Data Virtualisation (or Federated) Master Data

Figure 20 Master Data Sharing Example (Figure 77 DMBOK V2 Revised)
Data Integration and Management Strategies
There are various approaches to data modelling; these include the Data Vault and its satellite data tables and the implementation of a central hub in a knowledge graph for data integration. The knowledge graph facilitates integration across disparate sources and includes data cataloguing, trust rules, and data provenance. The importance of ontologies for the knowledge graph and the need to bridge structured and unstructured data for comprehensive user access. Additionally, the challenges of data harmonisation, particularly in the context of systems like SAP, are shared. Howard addresses the potential impact on standardised processes and the importance of navigating potential political and application-related obstacles.

Figure 21 Knowledge Areas in the Design and Enable phase of the Lifecycle

Figure 22 Knowledge Areas in the Create and Obtain phase of the Lifecycle
Data Sharing Architecture and Storage Solutions
The data sharing architecture involves bringing in and sharing data with external parties, leading to various considerations regarding data storage. Implementing it as a central hub presents numerous storage challenges, prompting the need to decide between using a knowledge graph, relational databases, or a data vault for staging. Additionally, the approach to understanding virtualisation and registry is important, as it simplifies the process of storing identifiers and pointers for federated and replicated communication.

Figure 23 Store and Maintain Knowledge Area
Data Management and Security in Data Warehouse
The data vault is crucial in handling Master Data and downstream processes. It’s important to support conform dimensions and manage slowly changing aspects, navigation hierarchies, and integration with data marts. The Master Data and Reference Data environments are key for business intelligence, providing self-service Power BI templates with Master Data, which can offer valuable insights. Master Data tables can be used as fact tables, adding an interesting dimension to the analysis. Additionally, there’s a need for a Master Data DQ dashboard, trend analysis, data security, and classification of data elements for protection techniques such as masking, encryption, and identifier management due to sensitive Personal Identifiable Information (PII) data.

Figure 24 Knowledge Areas in the Use phase of the Lifecycle
Challenges and Strategies in Implementing Master Data Systems
Various challenges and strategies are present for data science and Master Data Management. Affiliation management, product integration, and ontology in the knowledge graph are options for dealing with these challenges. Thus, the critical role of Master Data in understanding customers, suppliers, and data subjects, referencing a successful application in GDPR compliance, must be considered. Additionally, “a maniacal approach” to delivering the first version of Master Data in 90 days is suggested. This helps to tackle the need for a strong business case and stakeholder buy-in. Focusing on one project at a time will help build a solid foundation for Master Data Management.

Figure 25 Knowledge Areas in the Enhance phase of the Lifecycle

Figure 26 The Dispose phase of the Lifecycle

Figure 27 The Maniacal Focus to deliver Reference and Master Data value in 90 Days Incremental Elements

Figure 28 Building a Business Case

Figure 29 Portfolio vs Per Project
The Debate of Analytical vs Operational: A Discussion on Data Life Cycle
Howard notes the debate that revolves around analytical versus operational approaches. These can be analysed through the lens of the life cycle. Starting from planning, Data Governance, and data architecture, the executive perspective focuses on the time and effort invested in these stages, often leading to frustration over perceived inefficiencies. The process then moves on to data modelling and the eventual realisation of business value through use and enhancement. This highlights a key point: the only time business value is realised is during the use and enhancement phase, with the rest of the process being essentially funded by the business without immediate returns.

Figure 30 Analytical and Operational Modes
Strategic Data Management and Business Process Optimisation
The importance of focusing on analytical data over operational data will assist in achieving better value. Howard recommends starting with analytical data due to fewer politics and updates, allowing for a more focused approach. Limiting the scope, justifying with a business case, involving the right stakeholders, and managing scope and funding are some principles that can be applied to this end. Additionally, Howard stresses prioritising business outcomes and impact rather than technical details. He highlights the importance of gaining support from functional stakeholders rather than solely relying on CEO sponsorship.

Figure 31 Analytical and Operational Modes: Where do I start?

Figure 32 Analytical and Operational Modes: Where do I start? continued

Figure 33 90-Day Data Value-Driven Roadmap Maniacal Principles

Figure 34 Principle 2 Limit your scope

Figure 35 Principle 3 Justify with Business Case

Figure 36 Principle 4 Choose Critical Stakeholder
The Importance of Agile Data Management and Product Management Approach
Focus on agile Data Management with a 90-day strategy instead of a three-year plan. Use SWOT analysis to identify priorities, choose the best Master Data approach for specific KPIs, and justify, prove, and deliver on the proposed elements. By prioritising understanding the business first before diving into data literacy. It’s important to take a product management approach. Emphasise delivering value over time and constantly reassess and update the data strategy, focusing on 90-day strategies rather than long-term plans.
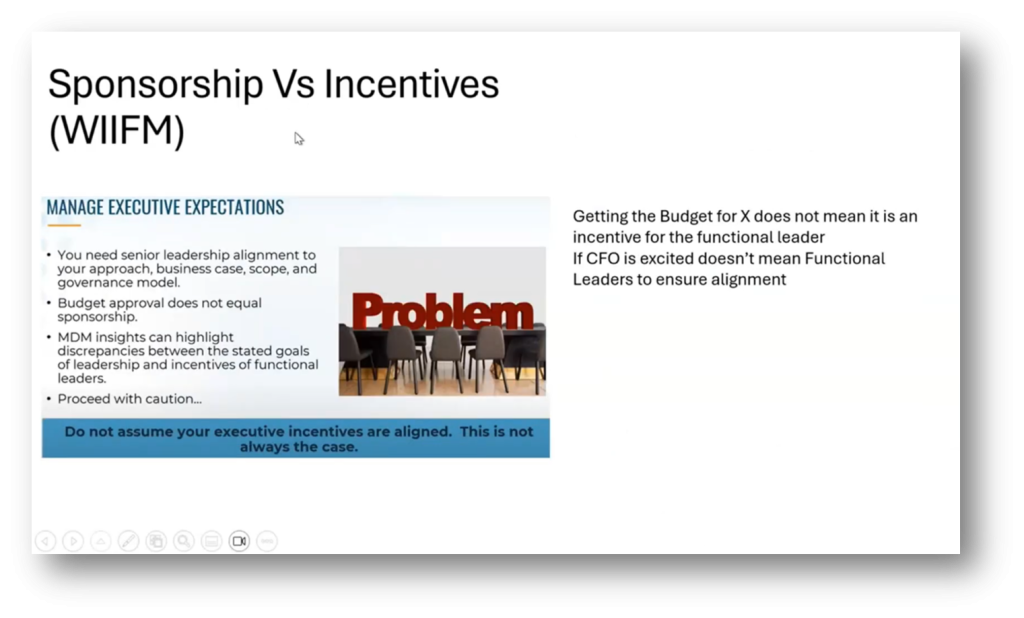
Figure 37 Principle 5 Choose Incentivised (WIIFM) Over Sponsor
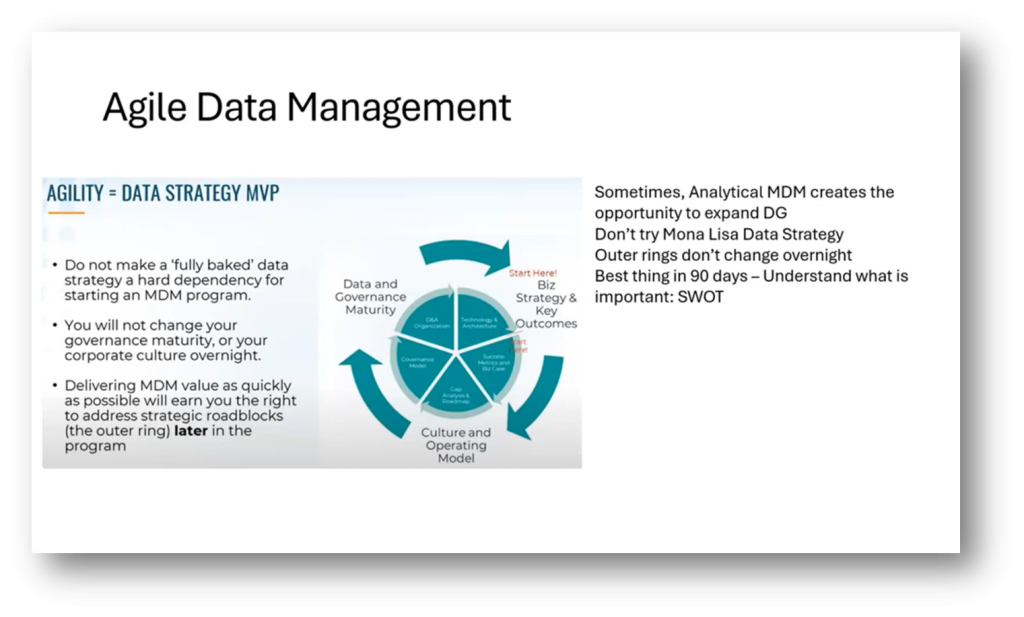
Figure 38 Principle 6 Apply Agile Principles

Figure 39 Principle 6 Apply Agile Principles Continued

Figure 40 Principle 6 Apply Agile Principles Continued
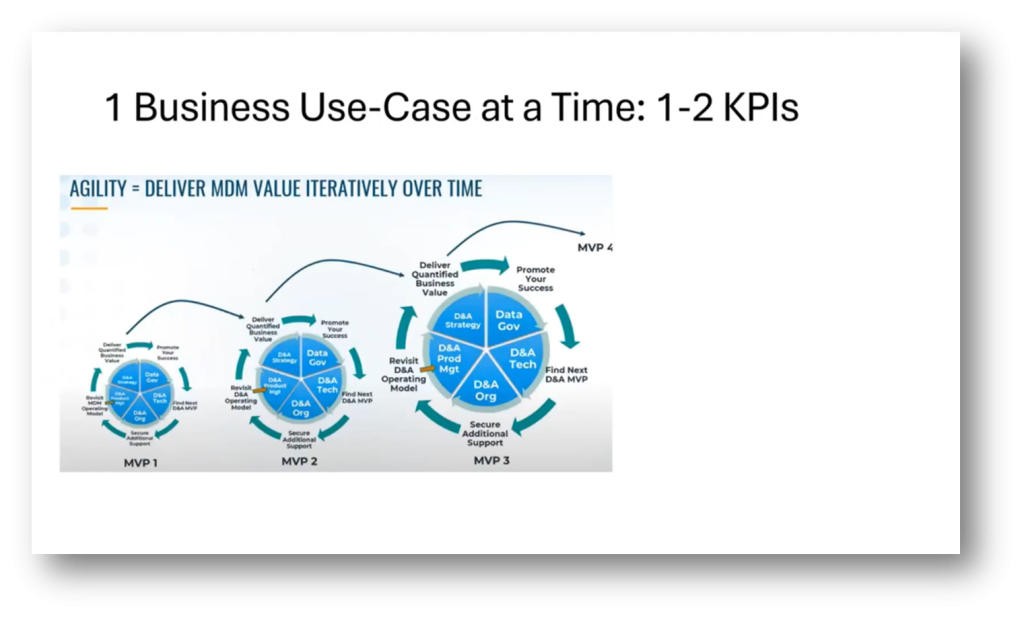
Figure 41 Principle 6 Apply Agile Principles Continued
Key Roles and Management in Data Management
The key roles in the Master Data program are the reference lead, business analyst, data/systems architect, system admin/business steward, and technology MVP. The team needs to assess whether the existing technology is sufficient for the task or if new technology needs to be purchased, considering the scale of the data. Scope management is critical, and the program lead must align with the business use case, carefully managing consultants’ expectations and ensuring that the scope of work and KPIs are clearly defined. Additionally, it’s important to secure funding for Master Data Management (MDM) initiatives.

Figure 42 Principle 6 Apply Agile Principles Continued

Figure 43 Principle 6 Apply Agile Principles Continued

Figure 44 Principle 7 You Manage the Scope
Data Architecture and Dependency Management
As a data architect, it’s important to understand the Subject Areas and their corresponding data processes and dependencies. Master Data should be in areas with the fewest dependencies, such as master product management and customer management. A recommended approach is to start with areas with no dependencies, then move to those with one or two dependencies, and finally build business intelligence (BI) from there.

Figure 45 Principle 7 You Manage the Scope

Figure 46 Data Flow Depicted as a Matrix (Figure 26 DMBOK V2 Revised
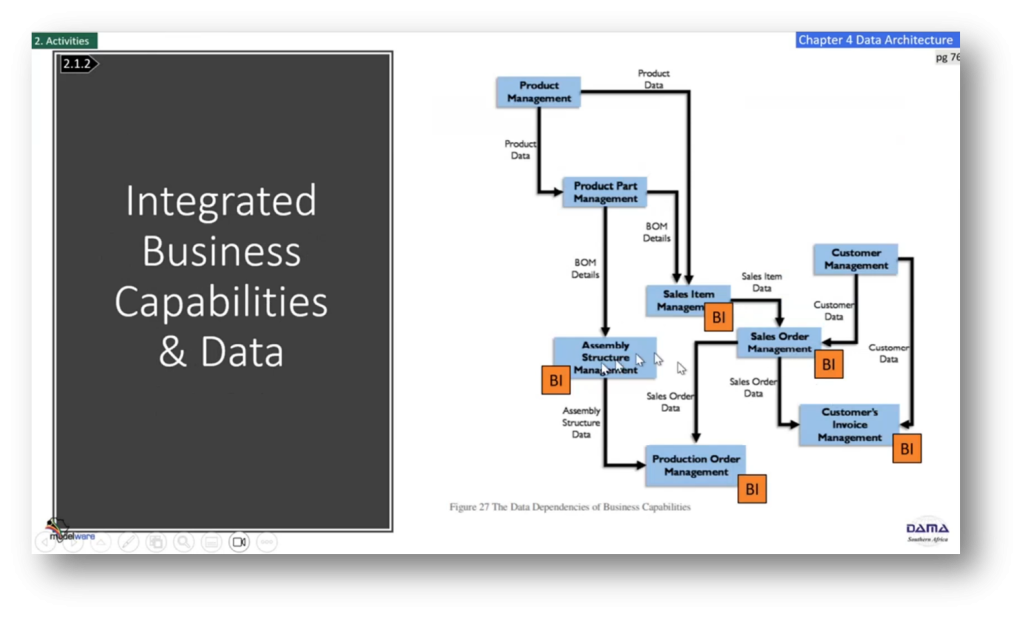
Figure 47 Data Flow Diagram Example (Figure 26 DMBOK V2 Revised)
Use of Master Data as Dimension Tables in Customer Analysis
Howard explains the process of building a surrogate key for customers and connecting various dimensions of customer data to the fact table. The discussion delves into the benefits of analysing customer data from different perspectives and dimensions, such as location, gender, and demographics. The potential for gaining insights into customer behaviour and creating customer segmentation using this approach is emphasised, highlighting the broader applications beyond typical business transactions.
The Importance of Business Process over Domain in Data Architecture
Howard shares on the idea of using business processes as the focal point for Data Management instead of focusing solely on data domains. Aligning Data Management with business value by incrementally building within appropriate domains will help to achieve specific business goals, such as increasing sales. The approach outlines aims to reduce the complexity of data integration, improve data quality, and demonstrate tangible value to stakeholders. Emphasising a shift towards being value-driven rather than domain-driven, Howard then highlights the need to prioritise business processes and functions over data domains.
Challenges and Strategies in Data Management
Implementing Master Data Management within a tight timeframe of 90-days can be challenging, but with a smaller time frame, it may smooth over the resistance faced in the business. The 90-day approach focuses on delivering a narrow scope to demonstrate value quickly, potentially involving more IT personnel initially rather than business stakeholders. Howard highlights the importance of starting with a narrow scope, emphasising the concept of “fit for purpose” for the initial 90-days and the potential pitfalls of getting too bogged down in extensive data cleaning without demonstrating immediate value to the business.
If you would like to join the discussion, please visit our community platform, the Data Professional Expedition.
Additionally, if you would like to watch the edited video on our YouTube please click here.
If you would like to be a guest speaker on a future webinar, kindly contact Debbie (social@modelwaresystems.com)
Don’t forget to join our exciting LinkedIn and Meetup data communities not to miss out!

